
Handling imbalanced datasets is a common challenge in machine learning, especially for classification tasks where the number of examples in different classes varies significantly. Imbalanced datasets can lead to biased models that perform poorly on minority classes. Here are several strategies to handle imbalanced datasets:
- Resampling Techniques: a. Oversampling: Increase the number of instances in the minority class by duplicating existing instances or generating synthetic data points. Popular methods include Synthetic Minority Over-sampling Technique (SMOTE) and ADASYN. b. Undersampling: Decrease the number of instances in the majority class by randomly removing samples. This can help balance the class distribution, but be cautious not to lose valuable information.
- Weighted Loss Function: Modify the loss function to assign higher weights to misclassified instances from the minority class. This gives the model more incentive to correctly classify minority class instances.
- Ensemble Methods:a. Bagging: Use ensemble techniques like Random Forest or EasyEnsemble, which can mitigate class imbalance by training multiple models on different subsets of the data and combining their predictions.b. Boosting: Algorithms like AdaBoost, XGBoost, and LightGBM can focus on misclassified instances, thus improving performance on the minority class.
- Cost-Sensitive Learning: Assign different misclassification costs for different classes. This encourages the model to minimize errors in the minority class.
- Generate Synthetic Data: Techniques like SMOTE and ADASYN generate synthetic instances for the minority class based on the existing data. These techniques can help the model learn the underlying patterns of the minority class better.
- Use Anomaly Detection Techniques: Treat the minority class as an anomaly detection problem and use techniques like One-Class SVM or isolation forests.
- Transfer Learning: Pre-train a model on a related dataset and fine-tune it on the imbalanced dataset. Transfer learning can help the model leverage knowledge from the larger dataset to perform better on the imbalanced one.
- Evaluation Metrics: Focus on evaluation metrics that are more informative for imbalanced datasets, such as precision, recall, F1-score, area under the ROC curve (AUC-ROC), and area under the precision-recall curve (AUC-PRC).
- Data Augmentation: For image-based datasets, data augmentation techniques like rotation, flipping, and cropping can help increase the effective size of the minority class.
- Combine Methods: Combining several of the above techniques can yield better results. However, careful consideration is required to avoid overfitting or introducing bias.
It’s essential to choose the strategy that best suits your dataset and problem domain. Experimentation and validation are crucial to find the right balance between techniques and prevent overfitting or underperformance on the minority class.
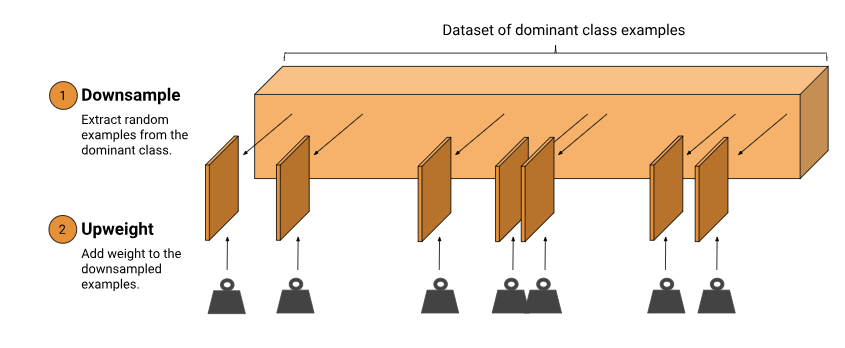
Downsampling and Upweighting
An effective way to handle imbalanced data is to downsample and upweight the majority class. Let’s start by defining those two new terms:
- Downsampling (in this context) means training on a disproportionately low subset of the majority class examples.
- Upweighting means adding an example weight to the downsampled class equal to the factor by which you downsampled.
Why Downsample and Upweight?
It may seem odd to add example weights after downsampling. We were trying to make our model improve on the minority class — why would we upweight the majority? These are the resulting changes:
- Faster convergence: During training, we see the minority class more often, which will help the model converge faster.
- Disk space: By consolidating the majority class into fewer examples with larger weights, we spend less disk space storing them. This savings allows more disk space for the minority class, so we can collect a greater number and a wider range of examples from that class.
- Calibration: Upweighting ensures our model is still calibrated; the outputs can still be interpreted as probabilities.