
How to Publish a kafka msg
Kafka from programmer point of view is: just topic, key, value , headers
https://kafka-python.readthedocs.io/en/master/apidoc/KafkaProducer.html
send(topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None)[source]
Publish a message to a topic.
| Parameters: |
|
|---|
Python code for easy understanding
>>> from kafka import KafkaProducer
>>> producer = KafkaProducer(bootstrap_servers='localhost:1234')
>>> for _ in range(100):
... producer.send('foobar', b'some_message_bytes')
>>> # Block until a single message is sent (or timeout)
>>> future = producer.send('foobar', b'another_message')
>>> result = future.get(timeout=60)
>>> # Block until all pending messages are at least put on the network
>>> # NOTE: This does not guarantee delivery or success! It is really
>>> # only useful if you configure internal batching using linger_ms
>>> producer.flush()
>>> # Use a key for hashed-partitioning
>>> producer.send('foobar', key=b'foo', value=b'bar')
>>> # Serialize json messages
>>> import json
>>> producer = KafkaProducer(value_serializer=lambda v: json.dumps(v).encode('utf-8'))
>>> producer.send('fizzbuzz', {'foo': 'bar'})
>>> # Serialize string keys
>>> producer = KafkaProducer(key_serializer=str.encode)
>>> producer.send('flipflap', key='ping', value=b'1234')
>>> # Compress messages
>>> producer = KafkaProducer(compression_type='gzip')
>>> for i in range(1000):
... producer.send('foobar', b'msg %d' % i)
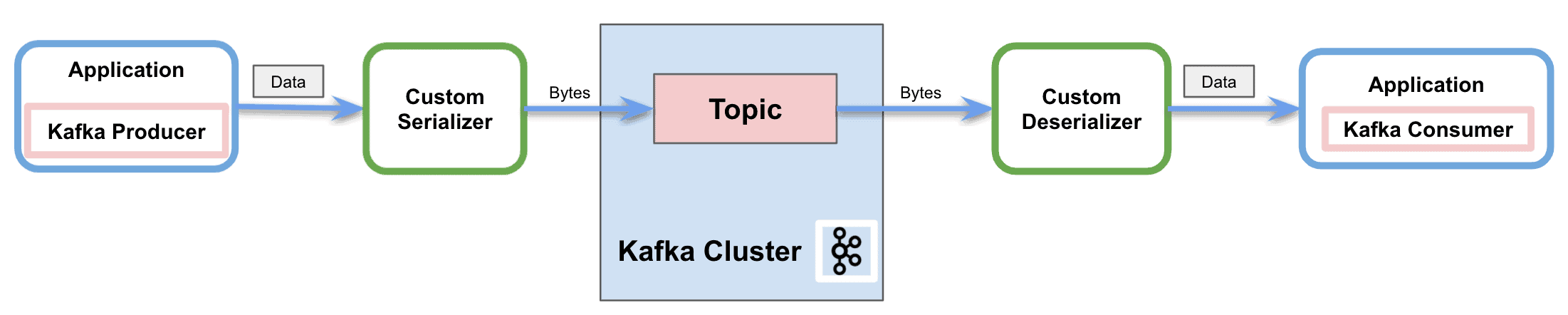
On the high level/kafka level, just key, value, headers, in order to send more structured/complicated data, we need specify serializer, which convert the pre-define structured msg into bytes ( that kafak needed at its API level), on the same token, on the consumer side, it need the same de-serilizer to convert bytes into well-defined struct.
How to receive kafka msg and de-serialize it
https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html
classkafka.KafkaConsumer(*topics, **configs)[source]
Consume records from a Kafka cluster.
The consumer will transparently handle the failure of servers in the Kafka cluster, and adapt as topic-partitions are created or migrate between brokers. It also interacts with the assigned kafka Group Coordinator node to allow multiple consumers to load balance consumption of topics (requires kafka >= 0.9.0.0).
The consumer is not thread safe and should not be shared across threads.
| Parameters: |
*topics (str) – optional list of topics to subscribe to. If not set, call |
|---|---|
| Keyword Arguments: | |
|
|
sample code
import threading import logging import time import jsonfrom kafka import KafkaConsumer, KafkaProducer
Create Class for Producer
You can send and receive strings if you remove the value_serializer and value_deserializer from the code below.
class Producer(threading.Thread): daemon = True def run(self): producer = KafkaProducer(bootstrap_servers='victoria.com:6667', value_serializer=lambda v: json.dumps(v).encode('utf-8')) while True: producer.send('my-topic', {"dataObjectID": "test1"}) producer.send('my-topic', {"dataObjectID": "test2"}) time.sleep(1)
Create Consumer Class
class Consumer(threading.Thread): daemon = True def run(self): consumer = KafkaConsumer(bootstrap_servers='victoria.com:6667', auto_offset_reset='earliest', value_deserializer=lambda m: json.loads(m.decode('utf-8'))) consumer.subscribe(['my-topic']) for message in consumer: print (message)
Headers
Kafka custom header properties enable you to add metadata to the Kafka message, which can then be used during message processing; for example, the header properties can carry information about the format of the data, such as a schema name.