
What is Apache Kafka? ( big picture)
I found the article http://www.confluent.io/blog/stream-data-platform-1/ ( from Jay Kreps) presented a very good big picture on what Kafka suppose to do: you can use Kafka to build a stream data platform. Here the pictures from that article.
The big idea is simple: many business processes can be modeled as a series of events (data/log stream) , thus we can publish those steam data ( topics) into Kafka, the interested subscribers can receive the stream and do whatever they want ( online process, store the data, etc), then these application can publish the derived stream( result) back to Kafka.


Kakfa internal details


The producer/Publisher choose which topic/partition to write ( to leader broker which was elected using zookeeper see below)
The consumer pull/fetch data ( specific log position) from leader broker . A partition is always consumed by a single consumer
- “leader” is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.
- “replicas” is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive.
- “isr” is the set of “in-sync” replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.

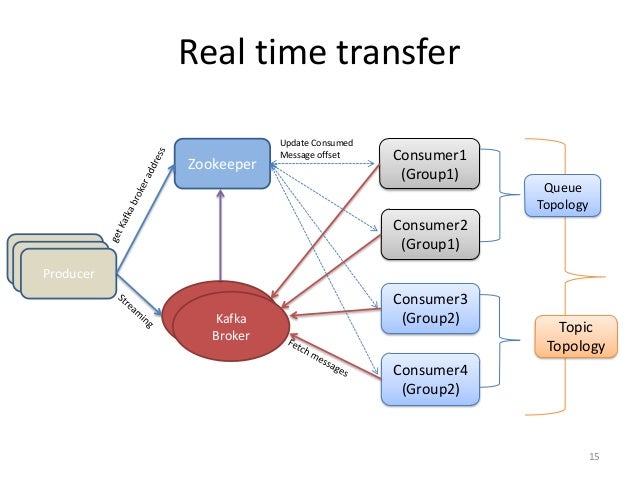
A good picture of zookeepr role here
Hands-on howto
see: http://kafka.apache.org/documentation.html#quickstart, it is no pain at all to start and play with kafka ( on debian 8)
install: wget http://mirror.symnds.com/software/Apache/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz tar -xzf kafka_2.11-0.9.0.0.tgz;
cd kafka_2.11-0.9.0.0
start zookeepr and kafka bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
create a topic bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
bin/kafka-topics.sh --list --zookeeper localhost:2181
produce a msg bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
consume a msg bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
References
http://www.confluent.io/blog/stream-data-platform-1/
http://www.confluent.io/blog/stream-data-platform-2/
http://www.slideshare.net/rahuldausa/introduction-to-kafka-and-zookeeper